企业常用GFS分布式存储系统
发表于:2024-11-30 作者:千家信息网编辑
千家信息网最后更新 2024年11月30日,GlusterFS简介开源的分布式文件系统由存储服务器,客户端以及NFS/Samba存储网关组成无元数据服务器GlusterFS特点扩展性和共性能高可用全局统一命名空间弹性卷管理基于标准协议Glust
千家信息网最后更新 2024年11月30日企业常用GFS分布式存储系统
GlusterFS简介
开源的分布式文件系统由存储服务器,客户端以及NFS/Samba存储网关组成无元数据服务器GlusterFS特点扩展性和共性能高可用全局统一命名空间弹性卷管理基于标准协议GlusterFS概述
Brick存储节点Volume卷fuse内核模块,用户端的交互性模块vfs虚拟Glusterd服务来理解一下这张图:
上面一层虚拟化管理层,想当于一个应用。缓存,读写头,条带卷,代理想当于API接口中间rdma传输 相当于一个驱动下面一层真实的设备 相 当于一个硬件clusterFS工作流程
弹性HASH算法通过HASH算法的到一个32位的整数划分位N个连续的子空间,每个空间对应一个Brick弹性HASH算法的优点保证 数据平均分布在每一个Brick中解决了对元数据服务器的依赖,进而解决了单点故障以及访问瓶颈通过HASH算法的到一个32位算法,去算去选择,因为你的每一个节点都存储一部分数据,你怎么去识别排序,通过算法。四个Brick节点的GlusterFS卷,平均分配232次方的区间的范围空间
通过hash算法去找到对应的brick节点的存储空间,去分配数据存储,去调用每一个节点数据clusterfs的卷类型
分布式卷复制卷分布式条带卷分布式复制卷条带复制卷分布式条带复制卷分布式卷
没有对文件进行分块处理通过扩展文件属性保存HASH值支持的底层文件系统有ext3,ext4,ZFS,XFS等**分布式卷具有如下特点**文件分布在不同的服务器,不具备冗余性更容易和廉价地扩展卷的大小单点故障会造成数据丢失依赖底层的数据保护我们有办法解决,因为它存的文件都是完整的,我们可以做个镜像卷,做个备份条带卷
根据偏移量将文件分成N块(N个条带节点),轮询的存储在每个Brickserver节点存储大文件时,性能尤为突出,不具备冗余性,类似Raid0**特点**数据被分割成更小块分布到块服务器群中的不同条带区分布减少负载且更小的文件加速了存取的速度没有数据冗余复制卷
同一个文件保存一份或多分副本复制模式因为保存副本,所以磁盘利用率较低多个节点的存储空间不一致,那么将按照木桶效应取最低节点的容量作为该卷的总容量**特点**卷中所有的服务器均保存一个完整的副本卷的副本数量可以有客户创建的时候决定至少由两个块服务器或更多服务器具备冗余性分布式条带卷
兼顾分布式卷和条带卷的功能主要用于大文件访问处理至少最少需要4台服务器分布式复制卷
兼顾分布式卷和复制卷的共呢用于需要冗余的情况下···## GFS分布式文件系统集群项目## 群集环境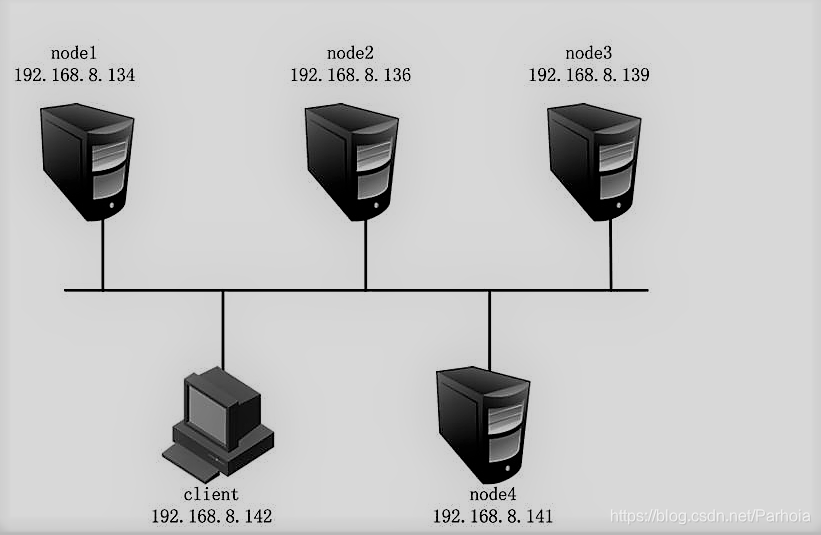## 卷类型| 卷名称 | 卷类型 | 空间大小 | Brick| |--|--|--|--||dis-volume | 分布式卷 |40G | node1(/b1)、node2(/b1) ||stripe-volume | 条带卷 | 40G|node1(/c1)、node2(/c1) || rep-volume | 复制卷 |20G |node3(/b1)、node4(/b1) || dis-stripe | 分布式条带卷 | 40G| node1(/d1)、node2(/d1)、node3(/d1)、node4(/d1) || dis-rep | 分布式复制卷 | 20G| node1(/e1)、node2(/e1)、node3(/e1)、node4(/e1) |## 实验准备#### 1、为四台服务器服务器每台添加4个磁盘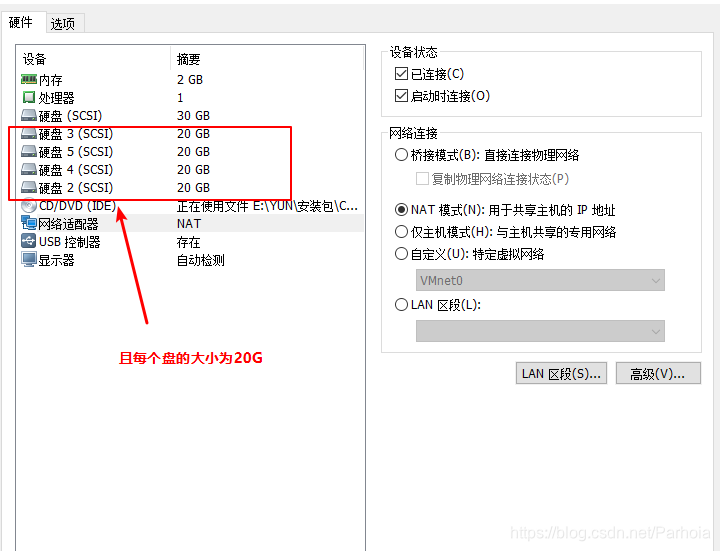#### 2、修改服务器的名称分别修改为node1、node2、node3、node4```sql[root@localhost ~]#hostnamectl set-hostname node1[root@localhost ~]# su3、将四台服务器上的磁盘格式化,并挂载
在这里我们使用脚本执行挂载
#进入opt目录[root@node1 ~]# cd /opt#磁盘格式化、挂载脚本[root@node1 opt]# vim a.sh#! /bin/bashecho "the disks exist list:"fdisk -l |grep '磁盘 /dev/sd[a-z]'echo "=================================================="PS3="chose which disk you want to create:"select VAR in `ls /dev/sd*|grep -o 'sd[b-z]'|uniq` quitdo case $VAR in sda) fdisk -l /dev/sda break ;; sd[b-z]) #create partitions echo "n p w" | fdisk /dev/$VAR #make filesystem mkfs.xfs -i size=512 /dev/${VAR}"1" &> /dev/null #mount the system mkdir -p /data/${VAR}"1" &> /dev/null echo -e "/dev/${VAR}"1" /data/${VAR}"1" xfs defaults 0 0\n" >> /etc/fstab mount -a &> /dev/null break ;; quit) break;; *) echo "wrong disk,please check again";; esacdone#给于脚本执行权限[root@node1 opt]# chmod +x a.sh将脚本通过scp推送到其他三台服务器上
scp a.sh root@192.168.45.134:/optscp a.sh root@192.168.45.130:/optscp a.sh root@192.168.45.136:/opt这个只是样本
[root@node1 opt]# ./a.shthe disks exist list:==================================================1) sdb2) sdc3) sdd4) sde5) quitchose which disk you want to create:1 //选择要格式化的盘Welcome to fdisk (util-linux 2.23.2).Changes will remain in memory only, until you decide to write them.Be careful before using the write command.Device does not contain a recognized partition tableBuilding a new DOS disklabel with disk identifier 0x37029e96.Command (m for help): Partition type: p primary (0 primary, 0 extended, 4 free) e extendedSelect (default p): Partition number (1-4, default 1): First sector (2048-41943039, default 2048): Using default value 2048Last sector, +sectors or +size{K,M,G} (2048-41943039, default 41943039): Using default value 41943039Partition 1 of type Linux and of size 20 GiB is setCommand (m for help): The partition table has been altered!Calling ioctl() to re-read partition table.Syncing disks.分别在四个服务器上查看挂载情况
4、设置hosts文件
在第一台node1上修改
#在文件末尾添加vim /etc/hosts192.168.45.133 node1192.168.45.130 node2192.168.45.134 node3192.168.45.136 node4通过scp将hosts文件推送给其他服务器和客户端
#将/etc/hosts文件推送给其他主机[root@node1 opt]# scp /etc/hosts root@192.168.45.130:/etc/hostsroot@192.168.45.130's password: hosts 100% 242 23.6KB/s 00:00 [root@node1 opt]# scp /etc/hosts root@192.168.45.134:/etc/hostsroot@192.168.45.134's password: hosts 100% 242 146.0KB/s 00:00 [root@node1 opt]# scp /etc/hosts root@192.168.45.136:/etc/hostsroot@192.168.45.136's password: hosts 在其他服务器上查看推送情况
关闭所有服务器和客户端的防火墙
[root@node1 ~]# systemctl stop firewalld.service [root@node1 ~]# setenforce 0在客户端和服务器上搭建yum仓库
#进入yum文件路径[root@node1 ~]# cd /etc/yum.repos.d/#创建一个空文件夹[root@node1 yum.repos.d]# mkdir abc#将CentOS-文件全部移到到abc下[root@node1 yum.repos.d]# mv CentOS-* abc#创建私有yum源[root@node1 yum.repos.d]# vim GLFS.repo[demo]name=demobaseurl=http://123.56.134.27/demogpgcheck=0enable=1[gfsrepo]name=gfsrepobaseurl=http://123.56.134.27/gfsrepogpgcheck=0enable=1#重新加载yum源[root@node1 yum.repos.d]# yum list安装必要软件包
[root@node1 yum.repos.d]# yum -y install glusterfs glusterfs-server glusterfs-fuse glusterfs-rdma在其他三台上进行同样的操作
在四台服务器上启动glusterd,并设置为开机自启动
[root@node1 yum.repos.d]# systemctl start glusterd.service [root@node1 yum.repos.d]# systemctl enable glusterd.service添加节点信息
[root@node1 yum.repos.d]# gluster peer probe node2peer probe: success. [root@node1 yum.repos.d]# gluster peer probe node3peer probe: success. [root@node1 yum.repos.d]# gluster peer probe node4peer probe: success. 在其他服务器上查看节点信息
[root@node1 yum.repos.d]# gluster peer status创建分布式卷
#创建分布式卷[root@node1 yum.repos.d]# gluster volume create dis-vol node1:/data/sdb1 node2:/data/sdb1 force#检查信息[root@node1 yum.repos.d]# gluster volume info dis-vol#查看分布式现有卷[root@node1 yum.repos.d]# gluster volume list#启动卷[root@node1 yum.repos.d]# gluster volume start dis-vol 在客户端上挂载
#递归创建挂载点[root@manager yum.repos.d]# mkdir -p /text/dis#将刚才创建的卷挂载到刚才创建的挂载点下[root@manager yum.repos.d]# mount.glusterfs node1:dis-vol /text/dis创建条带卷
#创建卷[root@node1 yum.repos.d]# gluster volume create stripe-vol stripe 2 node1:/data/sdc1 node2:/data/sdc1 force#查看现有卷[root@node1 yum.repos.d]# gluster volume listdis-volstripe-vol#启动条带卷[root@node1 yum.repos.d]# gluster volume start stripe-vol volume start: stripe-vol: success在客户端挂载
#创建挂载点[root@manager yum.repos.d]# mkdir /text/strip#挂载条带卷[root@manager yum.repos.d]# mount.glusterfs node1:/stripe-vol /text/strip/查看挂载情况
创建复制卷
#创建复制卷[root@node1 yum.repos.d]# gluster volume create rep-vol replica 2 node3:/data/sdb1 node4:/data/sdb1 forcevolume create: rep-vol: success: please start the volume to access data#开启复制卷[root@node1 yum.repos.d]# gluster volume start rep-vol volume start: rep-vol: success在客户机挂碍复制卷
[root@manager yum.repos.d]# mkdir /text/rep[root@manager yum.repos.d]# mount.glusterfs node3:rep-vol /text/rep查看挂载
创建分布式条带
#创建分布式条带卷[root@node1 yum.repos.d]# gluster volume create dis-stripe stripe 2 node1:/data/sdd1 node2:/data/sdd1 node3:/data/sdd1 node4:/data/sdd1 forcevolume create: dis-stripe: success: please start the volume to access data#启动分布式条带卷[root@node1 yum.repos.d]# gluster volume start dis-stripe volume start: dis-stripe: success在客户机上挂载
[root@manager yum.repos.d]# mkdir /text/dis-strip[root@manager yum.repos.d]# mount.glusterfs node4:dis-stripe /text/dis-strip/创建分布式复制卷
#创建分布式复制卷[root@node2 yum.repos.d]# gluster volume create dis-rep replica 2 node1:/data/sde1 node2:/data/sde1 node3:/data/sde1 node4:/data/sde1 forcevolume create: dis-rep: success: please start the volume to access data#开启复制卷[root@node2 yum.repos.d]# gluster volume start dis-rep volume start: dis-rep: success# 查看现有卷[root@node2 yum.repos.d]# gluster volume listdis-repdis-stripedis-volrep-volstripe-vol在客户端挂载
[root@manager yum.repos.d]# mkdir /text/dis-rep[root@manager yum.repos.d]# mount.glusterfs node3:dis-rep /text/dis-rep/查看挂载
------------------------上边我们完成了卷的创建和挂载-------------
现在我们来进行卷的测试
首先在客户机上创建5个40M的文件
[root@manager yum.repos.d]# dd if=/dev/zero of=/demo1.log bs=1M count=4040+0 records in40+0 records out41943040 bytes (42 MB) copied, 0.0175819 s, 2.4 GB/s[root@manager yum.repos.d]# dd if=/dev/zero of=/demo2.log bs=1M count=4040+0 records in40+0 records out41943040 bytes (42 MB) copied, 0.269746 s, 155 MB/s[root@manager yum.repos.d]# dd if=/dev/zero of=/demo3.log bs=1M count=4040+0 records in40+0 records out41943040 bytes (42 MB) copied, 0.34134 s, 123 MB/s[root@manager yum.repos.d]# dd if=/dev/zero of=/demo4.log bs=1M count=4040+0 records in40+0 records out41943040 bytes (42 MB) copied, 1.55335 s, 27.0 MB/s[root@manager yum.repos.d]# dd if=/dev/zero of=/demo5.log bs=1M count=4040+0 records in40+0 records out41943040 bytes (42 MB) copied, 1.47974 s, 28.3 MB/s然后复制5个文件到不同的卷上
[root@manager yum.repos.d]# cp /demo* /text/dis[root@manager yum.repos.d]# cp /demo* /text/strip[root@manager yum.repos.d]# cp /demo* /text/rep[root@manager yum.repos.d]# cp /demo* /text/dis-strip[root@manager yum.repos.d]# cp /demo* /text/dis-rep查看卷的内容
查看分布式卷
查看条带卷
查看复制卷
查看分布式条带卷
查看分布式复制卷


故障测试
关闭node2服务器观察结果
[root@manager yum.repos.d]# ls /text/dis dis-rep dis-strip rep strip[root@manager yum.repos.d]# ls /text/disdemo1.log demo2.log demo3.log demo4.log[root@manager yum.repos.d]# ls /text/dis-repdemo1.log demo2.log demo3.log demo4.log demo5.log[root@manager yum.repos.d]# ls /text/dis-strip/demo5.log[root@manager yum.repos.d]# ls /text/rep/demo1.log demo2.log demo3.log demo4.log demo5.log[root@manager yum.repos.d]# ls /text/strip/[root@manager yum.repos.d]# 结果表示:
- 分布卷缺少demo5.log文件
- 条带卷无法访问
- 复制卷正常访问
- 分布式条带卷缺少文件
- 分布式复制卷正常访问
删除卷
要删除卷需要先停止卷,在删除卷的时候,卷组必须处于开启状态
#停止卷[root@manager yum.repos.d]# gluster volume delete dis-vol#删除卷[root@manager yum.repos.d]# gluster volume delete dis-vol访问控制
#仅拒绝[root@manager yum.repos.d]# gluster volume set dis-vol auth.reject 192.168.45.133#仅允许[root@manager yum.repos.d]# gluster volume set dis-vol auth.allow 192.168.45.133
分布式
服务
文件
服务器
条带
客户
节点
数据
存储
空间
算法
客户端
冗余
磁盘
脚本
副本
情况
特点
系统
不同
数据库的安全要保护哪些东西
数据库安全各自的含义是什么
生产安全数据库录入
数据库的安全性及管理
数据库安全策略包含哪些
海淀数据库安全审计系统
建立农村房屋安全信息数据库
易用的数据库客户端支持安全管理
连接数据库失败ssl安全错误
数据库的锁怎样保障安全
在数据库0中检测到
稳定的数据库软件
网络安全的加强
数据库两张表怎么连接在一起
数据库最简单的实现
网络安全故障级别
计算机网络技术能做游戏吗
扬州网络安全要多少钱
溧阳软件开发
新吴区常见软件开发注意事项
云数据库有什么用
t-sql数据库
软件开发去ioe化
使用内容分析法做数据库
开易深圳科技数据库
硕士查重数据库包括本科论文吗
网络安全东南大学和上交大哪个好
如何切换网络服务器
方舟生存怎么一直进一个服务器
浪潮服务器mgmt管理
滁州初趣网络技术有限公司
php对数据库进行添加
一个公众号接入多个服务器
防火墙是网络安全中的( )
怎么连windows服务器
爬虫代理服务器
长宁区网络技术服务多少钱
数据库技术及应用第三版答案
网络安全教育测试卷判断题
服务器都有哪些用途


